
HAnDLE Project
Building the grounds for next-generation AI/ML acceleration
Funded with National Funds from
FCT: PTDC/EEI-HAC/30485/2017
FEDER: LISBOA-01-0145-FEDER-030485, POCI-01-0145-FEDER-030485
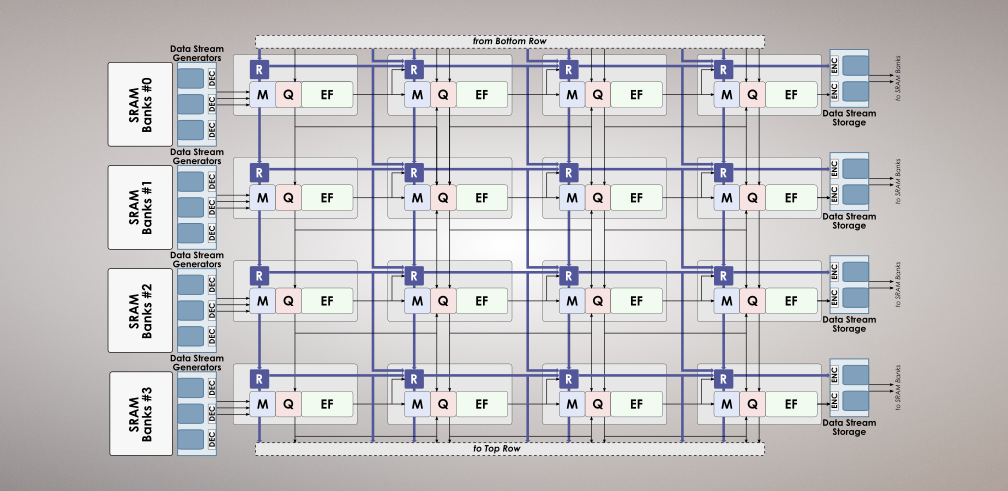
Context
DNNs and AI Frameworks
Recent advances in Deep Neural Networks (DNN) provided important breakthroughs in many domains, such as computer vision, speech recognition, natural language processing, drug discovery, genomics, etc. This has been achieved through deeper and non-uniform neural networks, by integrating new layer types (e.g, convolutional and/or recurrent layers), by investigating novel activation functions and through advances in the training methodologies. As a consequence of such novelties, and to overcome the computational complexity of DNNs, many new processing architectures (e.g., DaDianNao, PRIME, EIE, Google’s TPU) were recently proposed. However, such solutions usually rely on expensive implementation technologies, focus only on the inference phase, and/or are designed to only support a small subset of features available in many SW packages (e.g., in Convolutional Neural Networks (CNNs)). Additionally, and although most DNN SW libraries (e.g., TensorFlow, Caffe, Teano, Torch) already rely on GPUs to decrease the training time, application developers typically need to wait several weeks to train a DNN, a problem which is expected to worsen as DNNs become sparser, more complex and less susceptible to GPU acceleration.
Main Goals
Efficient AI/ML Acceleration
To overcome this issue, new techniques and computational approaches shall be proposed to support not only state-of-the-art DNNs, but also to be easily adaptable to ongoing advances in this import area. In particular, this project will focus on the exploitation of a set of techniques to: (i) mitigate the memory bandwidth problem of DNNs (efficient data management, data prefetching, online data augmentation); (ii) alleviate the computational complexity with minimal impact on the attained accuracy (approximate computing, decreased and adjustable numerical accuracy); (iii) efficiently support for sparse, irregular and non-uniform neural networks (through efficient execution control mechanisms, aided by reconfigurable processing structures); and (iv) provide a scalable solution using either a single FPGA (supporting FPGAs with different amounts of logic elements) or multiple FPGAs (through efficient inter-FPGA communication, workload partition and scheduling). Additionally, the research team will also work on new strategies to mitigate the computational complexity from the algorithmic side, by introducing additional network sparsity and by considering the sparsemax activation function.
Research Team Overview
To attain this challenging goal, this project joins together a set of researches with proven experience not only in the design of processor architectures, data management mechanisms, reconfigurable systems, and scheduling and workload balancing algorithms (including for DNNs); but also on the exploitation of DNNs for computer vision and natural language processing. Finally, it also counts with the collaboration of Portuguese companies, which will provide important applicational insights and real-world benchmarks.